
See what API testing solution came out on top in the GigaOm Radar Report. Get your free analyst report >>
Jump to Section
What Is Shift-Left Testing?

December 11, 2018
7 min read
The sooner you become aware of issues with your code, the less impact they will have. Dealing with them also results in lower expenses. Here, we unraveled the shift-left methodology and how to implement it in your business.
Jump to Section
Jump to Section
The Shift Left Testing Methodology
The movement to “shift-left” is about moving critical testing practices to earlier in the development lifecycle. This term is found especially in Agile, Continuous, and DevOps initiatives. So why do you need to perform early software testing?
Many testing activities occur late in the cycle, where it takes longer to figure out what went wrong and costs more to fix. Shifting left is about shifting the identification, and prevention, of defects to earlier. When you don’t, and wait to perform testing practices later in the development cycle, your non-functional business requirements in particular (i.e. security and performance testing) are so fundamentally ingrained in your code that all you can really do is patch them up rather than fix them properly.
When Do Bugs Enter the Code?
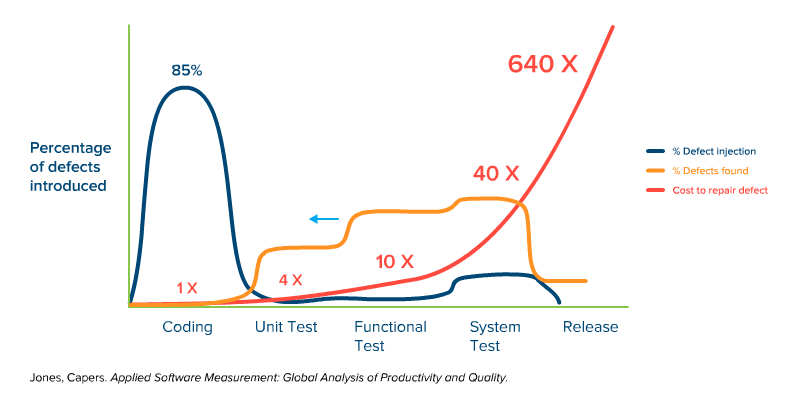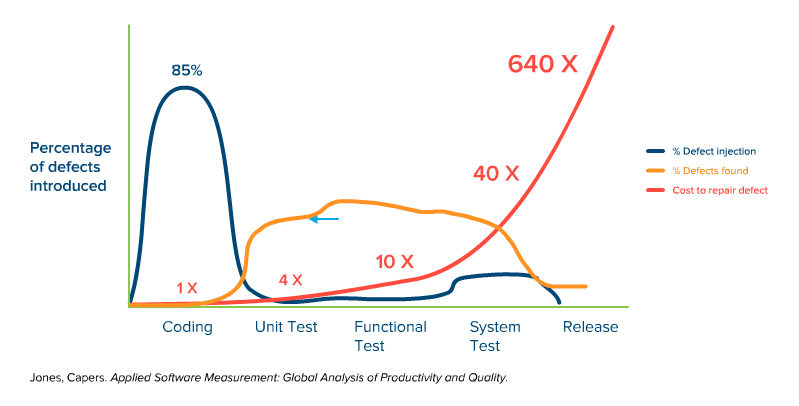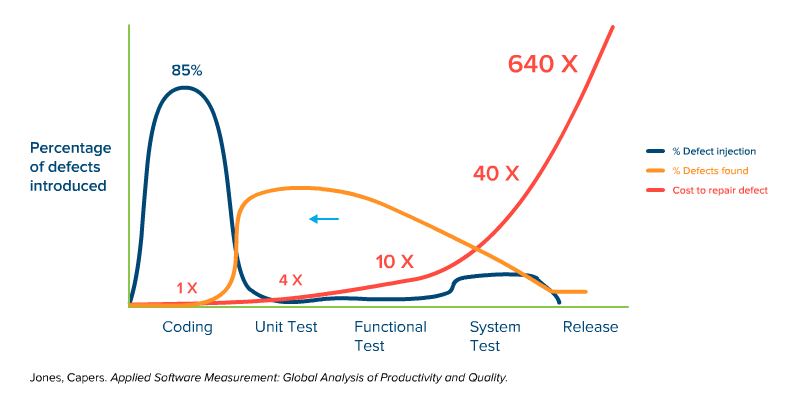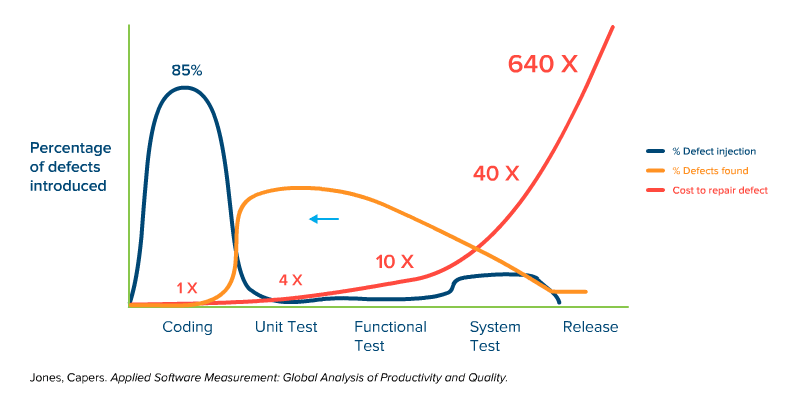
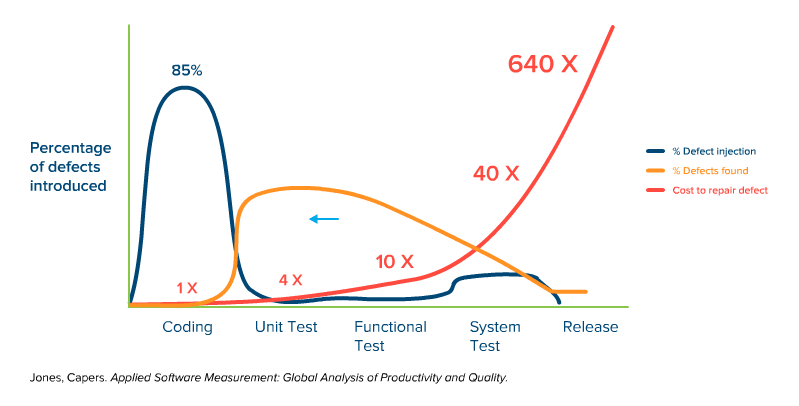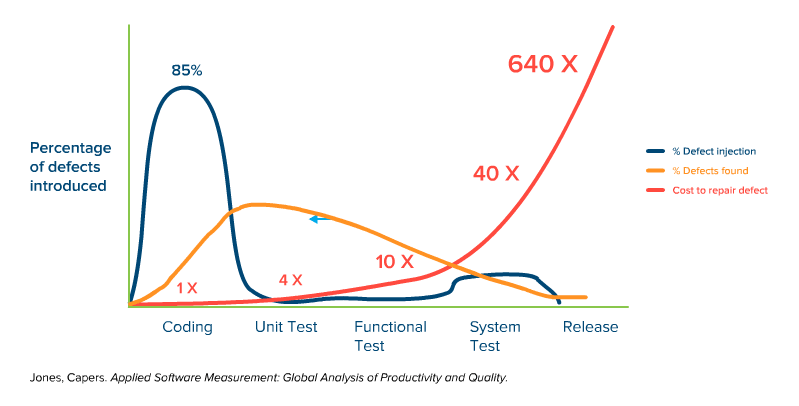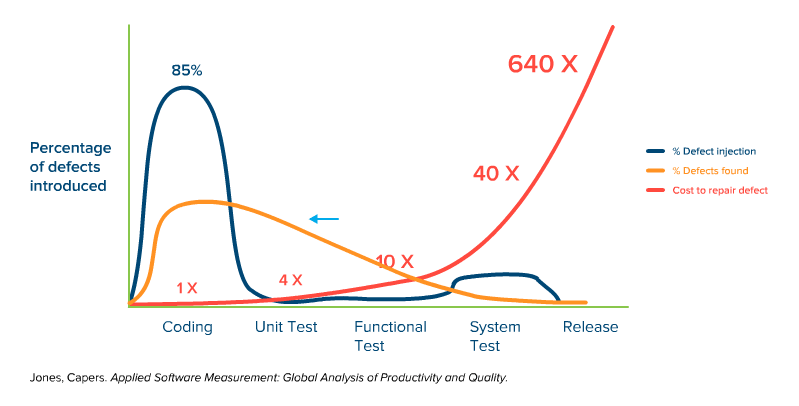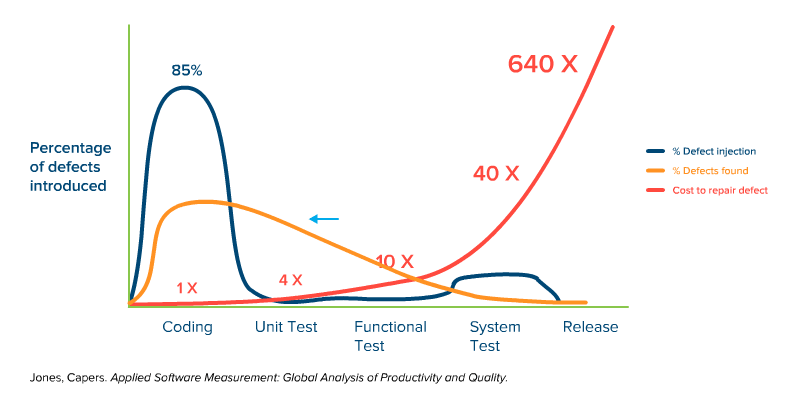
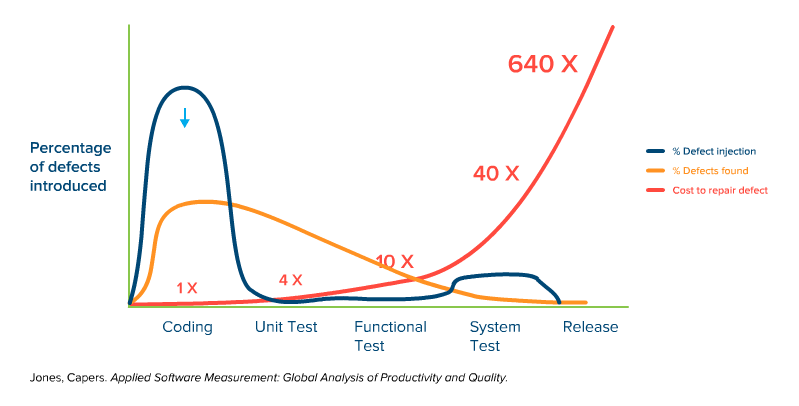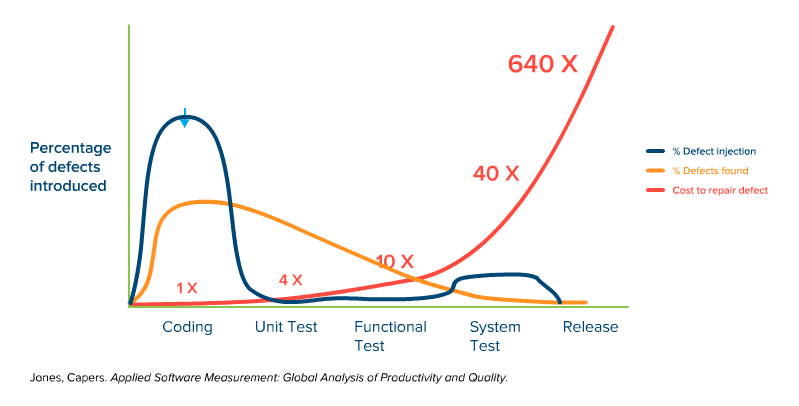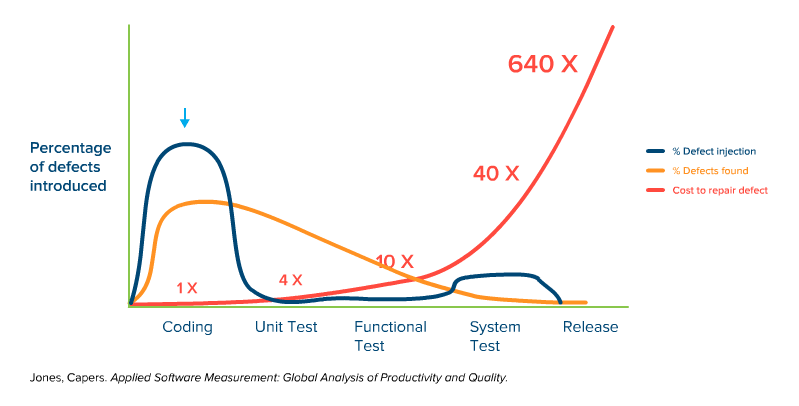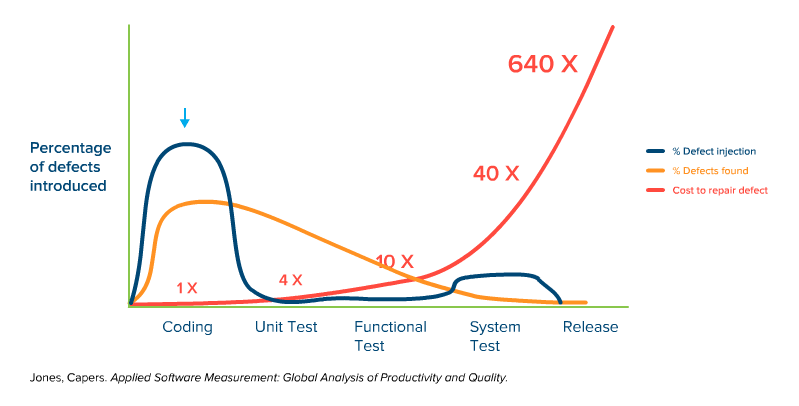
The shift left testing strategy is well illustrated in the somewhat-famous graph from Capers Jones, that shows the increasing cost of bugs/defects being introduced into the software, at each phase of software development. The first part of the graph shows that the vast majority of bugs come in during the coding phase, which is to be expected.
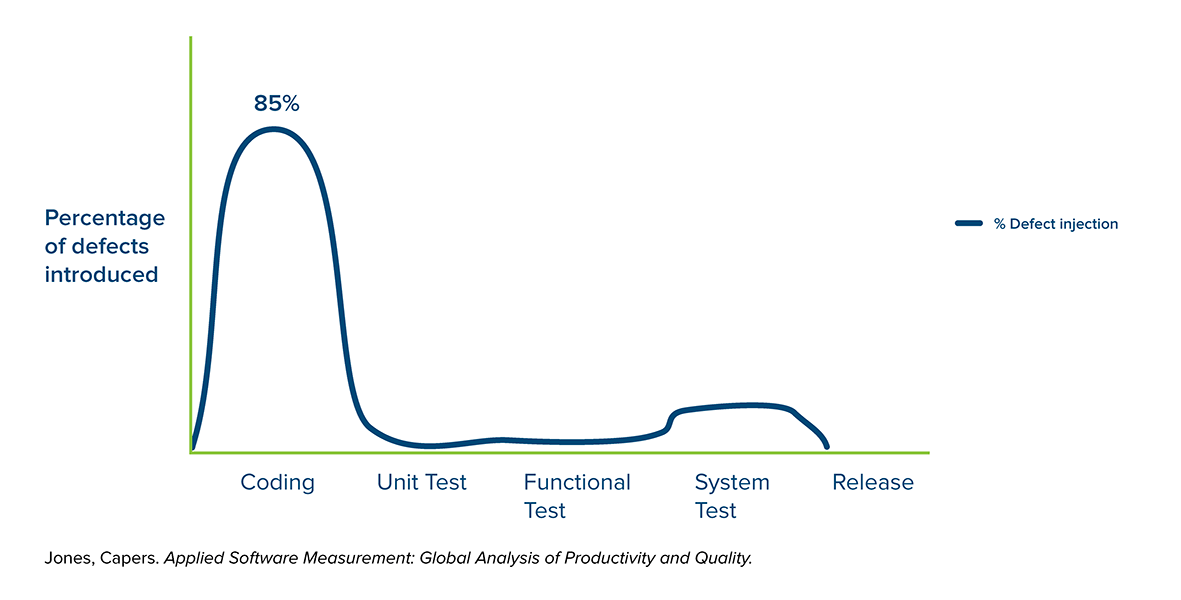
Whether they make actual mistakes, or misunderstand the requirements, or don’t think through the ramifications of a particular piece of code, developers introduce defects as the code is produced.
Defects are also introduced into the application when it’s time to fit the pieces together, especially if multiple teams are involved (and as modern architectures like microservices get more complex).
When Are Those Bugs Found?
It starts to get interesting when we overlay the line that shows where defects are foundon top of the graph of bugs being introduced.
Notice that it is basically an inverse of the first line:
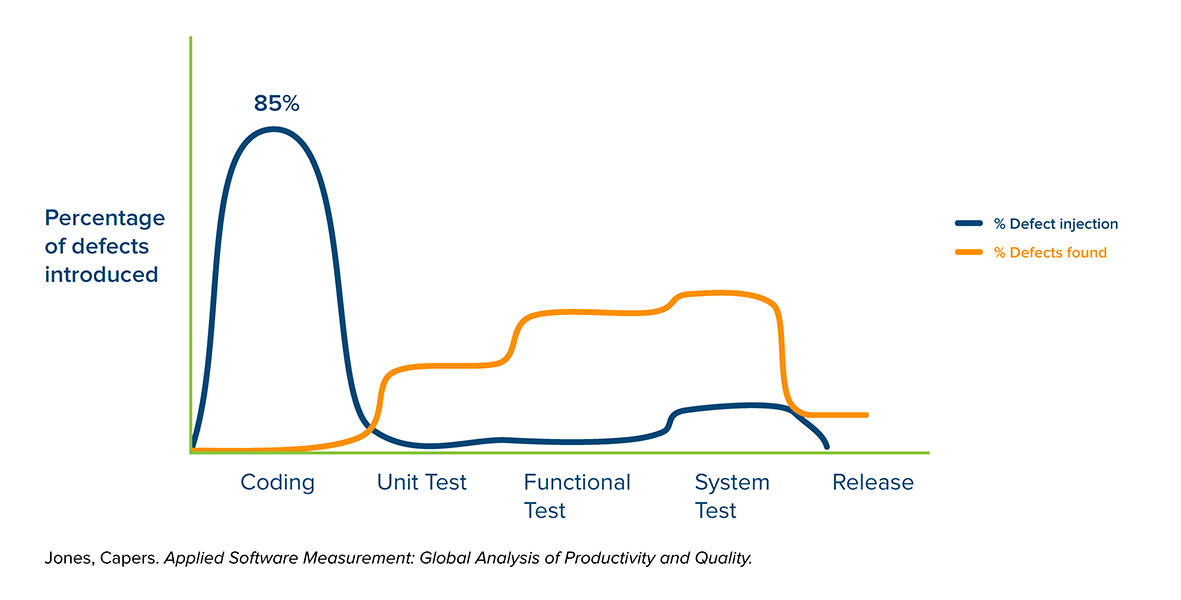
Of course, this isn’t surprising, because typically you find bugs when you start testing, and it can be difficult without a proper infrastructure to begin testing before everything is ready (more on that later). What we do see here is that the bugs are mostly introduced during coding, but almost never found at that phase.
What Does It Cost to Fix Bugs?
Because the majority of bugs are introduced during coding, but not discovered until a later phase, it becomes important to understand the difference it costs to fix defects at each phase of development. This is represented below:
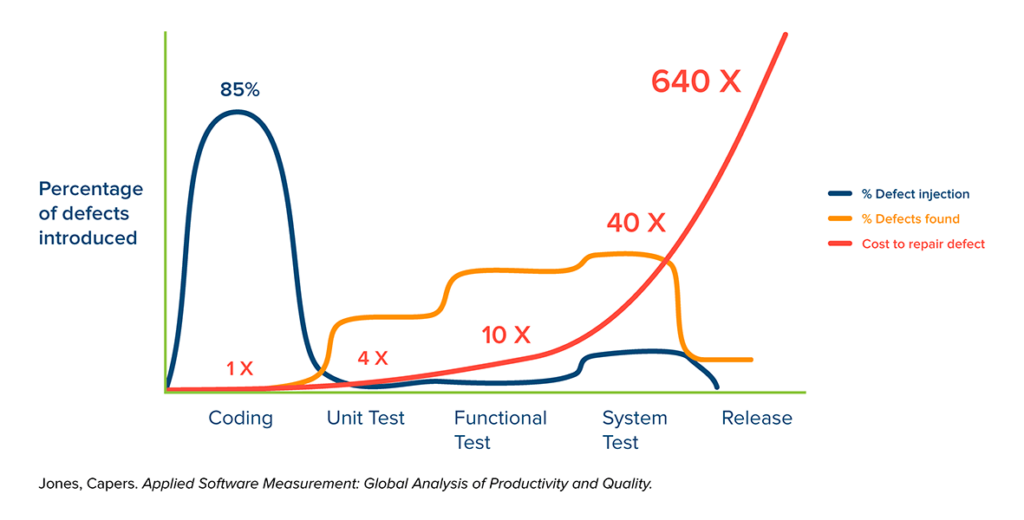
Now it starts to get interesting, as we see a nasty progression of cost that dramatically increases the later the defect is found. Letting a bug sneak through to system testing is 40x the cost of finding it during coding, or 10x more costly than finding that same bug during unit testing. And it just gets ridiculously expensive when you look at the numbers of letting bugs slip through to the actual deployment.
There are reasons for this cost escalation, including:
- The time and effort it takes to track down the problem. The more complex (bigger) the test case is, the more difficult it is to figure out which part of it is the real troublemaker.
- The challenge of reproducing defects on a developer’s desktop, as dependent systems like databases or third-party APIs are brought in. (It’s common for organizations to experience a multi-week lag between defect detection and defect remediation in these situations.)
- The impact of the change that is needed to fix a defect. If it’s a simple bug, it doesn’t matter so much. But if you have done it in many places, or you’ve used the wrong framework, or you’ve built code that isn’t scalable enough for the expected load, or that can’t be secured…
Test Early, Test often: The Shift-Left Approach
Now watch the orange line added to the graph below, as it illustrates a proposed defect detection cycle that is based on earlier testing (shifted left):
You can watch the orange detection curve growing larger on the cheap side of things and smaller on the expensive side, giving us a pretty significant cost reduction.
The shift-left relies on a more mature development practice, for example one based on the software testing pyramid (developers creating a set of unit tests that cover the code reasonably well, and functional testers and API testers doing as much as they can and minimizing reliance on late-cycle testing so you have just enough manual/UI tests to prove that everything is working). This way, the late cycle tests are there to prove functionality, not to find bugs. Test-early, test-often is the mantra of the shift-lefter.
Shifting Even Farther Left
Some organizations shifting left stop at this point. But you get even more value when you push even further left, into coding itself. After all, this is where bugs are introduced — so let’s start looking for them while development is still working. This is where we benefit from static code analysis — by finding defects even farther to the left, where defects are cheapest to fix:
With static analysis, you can start finding bugs during the actual coding phase, when the cost of finding bugs is as low as it can get.
As you can plainly see, finding things before “testing” begins is the most cost-effective. It’s the most time-effective as well, since it doesn’t leave developers with any issues around trying to reproduce bugs or understand the failures. Being able to shrink a defect remediation cycle from days-or-weeks to hours-or-minutes is tremendously helpful.
Beware of Shifting the Burden to the Developer
But there is one danger in this step, which is accidentally putting too much testing burden onto the software developers. The important thing to remember as you look at the graph, is that while the cost of defect remediation gets drastically higher as you go right, the resources on the left have possibly the highest cost of any in the software lifecycle – not to mention that you are taking them away from focusing on developing functionality.
So you have to do the right thing and take all of this to the next level. You don’t just want to find defects earlier, you actually want to decrease the number of defects you’re putting into the application in the first place. See the graph below, with the lovely reduced bubble on the left.
But wait, there’s a trap! If you were rewarding people for finding and fixing bugs, now they will find fewer, which is actually what you want, but only if you really have reduced the number of bugs you’re introducing in the first place. Measuring the number of defects that make it into the field is probably a more useful metric.
How Do You Shift Left?
Ok, so this is at the very core of everything that we do at Parasoft. But for the sake of brevity, the shift left testing approach breaks down into two main activities.
Apply Development Testing Best Practices
Doing earlier stage development practices, such as static code analysis and unit testing, helps both identify and prevent defects earlier in the process.
It’s important to remember that the goal is not to find bugs but to reduce the number of bugs (especially those that make it into the release). Ultimately, creating fewer bugs in the first place is far more valuable than finding more bugs, and it’s a lot cheaper. That’s why safety-critical coding standards on a proactive, preventative approach by flagging code that may “work” but still not be safe.
Coding standards are the software equivalent of engineering standards, and they are key to reducing the volume of bugs (in addition to finding bugs earlier), to support and get the most value out of your shift left initiative. Coding standards are the embodiment of software engineering knowledge that helps you avoid bad/dangerous/insecure code. To use them, you apply static code analysis.
For software security, this is especially important to successfully harden your software. You want to build security into your code, not test it. Coding standards let you build a more secure application from the beginning (i.e. secure by design), which is both a good idea and a requirement if you’re subject to regulations like GDPR.
Leverage Service Virtualization to Enable Continuous Testing
Next, you must take the tests that were created at all stages, including the later stages, of the development process, and execute them continuously moving forward. This is critical for teams that are adopting agile development practices to provide continuous feedback throughout the development process. Unit tests can easily be executed continuously, but shifting left the execution of later-stage functional tests is often difficult due to external system dependencies, and this is where you can leverage service virtualization to enable continuous testing.
Service virtualization enables you to simulate dependent systems that might have limited availability, such as mainframes, access fees, 3rd party services, or perhaps systems that just aren’t ready yet. By simulating them, you can perform functional testing without having the whole system available, and you can shift-left test execution all the way to the development desktop.
In terms of service virtualization in performance testing, service virtualization enables you to test before everything is ready, and without having a complete lab of everything in the system. You can even run all kinds of what-if scenarios, like what if the appserver is fast and the database slow (something difficult to make happen in the real world). Or what if my server starts throwing funny errors like a 500 error — how will that affect system performance?
You can push the system as hard as you like and beyond, and do it as early as possible. (Learn more about how to shift-left your performance testing.)
Similarly, you can start doing your security testing earlier. Decoupling from physical systems allows you to do something even more interesting, which is to make the simulated systems behave in an evil fashion. Now you can REALLY get into security testing… Instead of just poking at your system for tainted data and DDoS, you can have a system flood you with packets, send malformed data, or any of the many other exploits commonly used by attackers. So not only can you test earlier (left-er), but you can also test much deeper than is possible with a test lab or production system.
Summary
The quality assurance processes that have proven effective over many decades can be utilized to dramatically improve quality while saving time and money.
When you shift left by leveraging modern software testing technologies, you can achieve software that is safe, reliable, and secure. By shifting testing left, you can reduce the cost of testing by finding bugs earlier, when it’s cheaper, while also reducing the number of bugs you put into the code in the first place.
Software Testing Methodologies Guide: Maximize Quality, Compliance, Safety, & Security
Recommended Content


