
See what API testing solution came out on top in the GigaOm Radar Report. Get your free analyst report >>
Jump to Section
How to Prevent Buffer Overflow & Other Memory Management Bugs

November 28, 2023
10 min read
When the volume of data exceeds the storage capacity of the memory buffer, you experience a buffer overflow. Check out how the static analysis checker feature in the Parasoft C/C++ solution can help you manage errors from buffer overflows.
Jump to Section
Jump to Section
Memory management is fraught with danger, especially in C and C++. In fact, bugs associated with memory management weaknesses make up a sizeable part of the CWE Top 25. Eight of the top 25 are directly related to buffer overflows, poor pointers, and memory management.
The top software weakness by a large margin is CWE-119, “Improper Restriction of Operations within the Bounds of a Memory Buffer.” These types of errors figure prominently in safety and security issues in all sorts of software, including safety-critical applications in automobiles, medical devices, and avionics.
Here are the memory errors related to common weakness enumerations from the CWE Top 25:
| Rank | ID | Name |
|---|---|---|
| [1] | CWE-787 | Out-of-bounds Write |
| [4] | CWE-416 | Use After Free |
| [7] | CWE-125 | Out of bounds Read |
| [12] | CWE-476 | NULL Pointer Dereference |
| [14] | CWE-190 | Integer Overflow or Wraparound |
| [17] | CWE-119 | Improper Restriction of Operations within the Bounds of a Memory Buffer |
Although these errors have plagued C, C++, and other languages for decades, they still occur with increasing numbers today. They’re dangerous bugs in terms of consequences to quality, safety, and reliability, and their presence is a leading cause of security vulnerabilities.
What Are Buffer Overflows?
A buffer overflow occurs when more data is written to a piece of memory, or buffer, than it can hold, for example, if you attempt to put 12 letters in a box that only holds 10. This can lead to the overwriting of adjacent memory spaces, causing unpredictable behavior in a program.
Buffer overflow errors can significantly impact both the quality, security, and reliability of software. From a security perspective, malicious actors can exploit buffer overflow errors to execute arbitrary code or disrupt a system’s operations. This is because when a buffer overflow occurs, an attacker may be able to control what data is written beyond the buffer, potentially allowing them to alter the execution flow of the program.
Therefore, it’s crucial for developers to implement robust data handling and properly test their software to prevent buffer overflow errors and maintain the integrity and security of their software.
Leading Cause of Security Vulnerabilities
Microsoft discovered that for the last 12 years, over 70% of the security vulnerabilities in their products were due to memory safety issues. These types of bugs are the largest attack surface for their application and hackers are using it. According to their research, the top root causes of security attacks were heap out-of-bounds, use-after-free, and uninitialized use. As they point out, the vulnerability classes have existed for 20 years or more and are still prevalent today.
In a similar way, Google found that 70% of the security vulnerabilities in the Chromium project, the open source base for the Chrome browser, are due to these same memory management issues. Their top root cause was also use-after-free with other unsafe memory management coming in second.
Given these examples of real-world findings, it’s critical that software teams take these types of errors seriously. Luckily, there are ways to prevent and detect these types of issues with static analysis that is effective and efficient.
How Memory Management Errors Turn Into Security Vulnerabilities
In most cases, memory management errors are the result of poor programming practices with the use of pointers in C/C++ and accessing memory directly. In other cases, it’s related to making poor assumptions about the length and content of data.
These software weaknesses are most often exploited with tainted data, data from outside the application that hasn’t been checked for length or format. The infamous Heartbleed vulnerability is a case of exploiting a buffer overflow. Technically, it’s a buffer overread. As we discussed in our previous blog about SQL injections, the use of input that’s unchecked and unconstrained is a security risk.
Let’s consider some of the major categories of memory management software weaknesses. The overarching one is CWE-119: Improper Restriction of Operations Within the Bounds of a Memory Buffer.
Buffer Overflow
Programming languages, most often C and C++, that allow direct access to memory and don’t automatically verify the locations accessed are valid and prone to memory corruption errors. This corruption can occur in data and code areas of memory, which can expose sensitive information, lead to unintended code execution, or cause an application to crash.
The following example shows a classic case of a buffer overflow from CWE-120:
char last_name[20];
printf ("Enter your last name: ");
scanf ("%s", last_name);In this case, there is no restriction on the user input from scanf() yet the limit on the length of last_name is 20 characters. Entering a last name of more than 20 characters ends up copying the user input into memory beyond the limits of the buffer last_name. Here’s a more subtle example from CWE-119:
void host_lookup(char *user_supplied_addr){
struct hostent *hp;
in_addr_t *addr;
char hostname[64];
in_addr_t inet_addr(const char *cp);
/*routine that ensures user_supplied_addr is in the right format for conversion */
validate_addr_form(user_supplied_addr);
addr = inet_addr(user_supplied_addr);
hp = gethostbyaddr( addr, sizeof(struct in_addr), AF_INET);
strcpy(hostname, hp->h_name);
}This function takes a user-supplied string containing an IP address, for example, 127.0.0.1, and retrieves the hostname for it.
The function validates the user input (good!) but doesn’t check the output of gethostbyaddr() (bad!) In this case, a long hostname is enough to overflow the hostname buffer that’s currently limited to 64 characters. Note that if gethostaddr() returns a null when a hostname can’t be found, there’s also a null pointer dereference error as well!
Use-After-Free Errors
Interestingly, Microsoft, in their study, observed that use-after-free errors were the most common memory management issues they faced. As the name implies, the error relates to the use of pointers in the case of C/C++ that access previously freed memory. C and C++ usually rely on the developer to manage memory allocation, which can often be tricky to do completely correctly. As the following example from CWE-416 shows, it’s often easy to assume a pointer is still valid:
char* ptr = (char*)malloc (SIZE);
if (err) {
abrt = 1;
free(ptr);
}
...
if (abrt) {
logError("operation aborted before commit", ptr);
}In the above example, the pointer ptr is free if an err is true, but then is dereferenced later, after being freed, if abrt is true, which is set to true if err is true. This might seem contrived, but if there is a lot of code between these two code snippets, it’s easy to overlook. In addition, this might only occur in an error condition that doesn’t get properly tested.
NULL Pointer Dereference
Another common software weakness is using pointers or objects in C++ and Java that are expected to be valid but are NULL. Although these dereferences are caught as exceptions in languages like Java, they can cause an application to halt, exit, or crash. Take the following example, in Java, from CWE-476:
String cmd = System.getProperty("cmd");
cmd = cmd.trim();This looks innocuous since the developer might assume that the getProperty() method always returns something. In fact, if the property “cmd” doesn’t exist, a NULL is returned causing a NULL dereference exception when it’s used. Although this sounds benign, it can lead to disastrous outcomes.
In rare circumstances, when NULL is equivalent to the 0x0 memory address and privileged code can access it, then writing or reading memory is possible, which may lead to code execution.
Effective Mitigation Strategies
There are several mitigations available that developers should implement. Primarily, developers need to ensure pointers are valid for languages like C and C++ with verified logic and thorough checking.
For all languages, it’s imperative that any code or libraries that manipulate memory validate input parameters to prevent out-of-bounds access. Below are some mitigating options that are available. But developers shouldn’t rely on them to make up for poor programming practices.
Programming Language Choice
Some languages provide built-in protection against overflows such as Ada and C#.
Use of Safe Libraries
Using libraries, like the Safe C String Library, that provide built-in checks to prevent memory errors is available. However, not all buffer overflows are the result of string manipulation. Barring this, programmers should always resort to functions that take the length of buffers as arguments, for example, strncpy() versus strcpy().
Compilation and Runtime Hardening
This approach makes use of compilation options that add code to the application to monitor pointer usages. This added code can prevent overflow errors from occurring at runtime.
Execution Environment Hardening
Operating systems have options to prevent execution of code in data areas of an application, such as a stack overflow with code injection. There are also options to randomly arrange the memory mapping to prevent hackers from predicting where exploitable code may reside.
Despite these mitigations, there is no replacement for proper coding practices to avoid buffer overflows in the first place. Therefore, detection and prevention are critical to reducing the risks of these software weaknesses.
Shift the Detection and Elimination of Buffer Overflows
Adopting a DevSecOps approach to software development means integrating security into all aspects of the DevOps pipeline. Just as quality processes like code analysis and unit testing are pushed as early as possible in SDLC, the same is true for security.
Buffer overflows and other memory management errors could be a thing of the past if development teams adopted such an approach more broadly. As Google and Microsoft’s research shows, these errors still make up 70% of their security vulnerabilities. Regardless, let’s outline an approach that prevents them as early as possible.
Finding and fixing memory management errors pays off big time compared to patching a released application. The detect and prevent approach outlined below is based on shifting left the mitigation of buffer overflows to the earliest stages of development. And reinforcing this with detection via static code analysis.
Detection
Detecting memory management errors relies on static analysis to find these types of vulnerabilities in the source code. Detection happens at the developer’s desktop and in the build system. It can include existing, legacy, and third-party code.
Detecting security issues on a continuous basis ensures finding any issues that:
- Developers missed in the IDE.
- Exist in code that predates your new detect-and-prevent approach.
The recommended approach is a trust-but-verify model. Security analysis is done at the IDE level where developers make real-time decisions based on the reports they get. Next, verify at the build level. Ideally, the goal at build level isn’t to find vulnerabilities. It’s to verify that the system is clean.
Parasoft C/C++test includes static analysis checkers for these types of memory management errors, including buffer overflows. Consider the following example taken from C/C++ test.
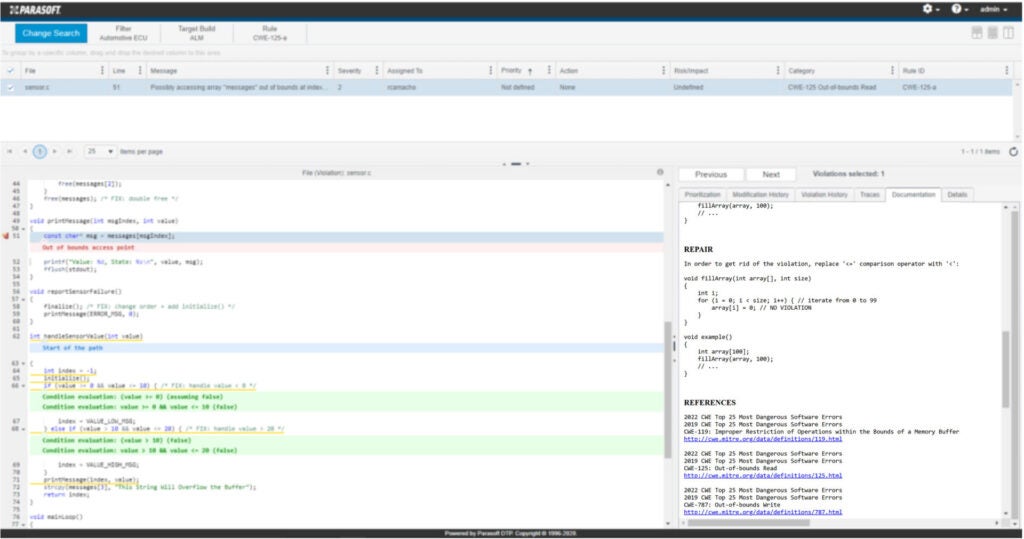
Zooming in on the details, the function printMessage() error detects the error:
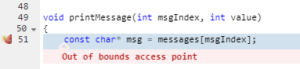
Parasoft C/C++test also provides trace information on how the tool arrived at this warning:
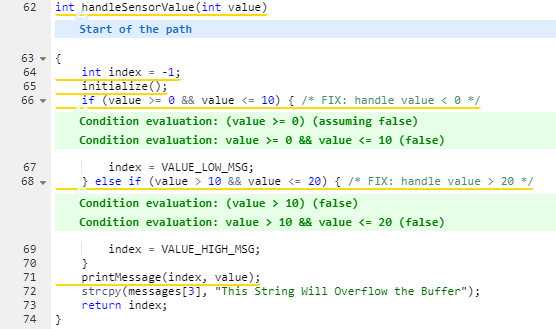
The sidebar shows details about how to repair this vulnerability along with appropriate references:
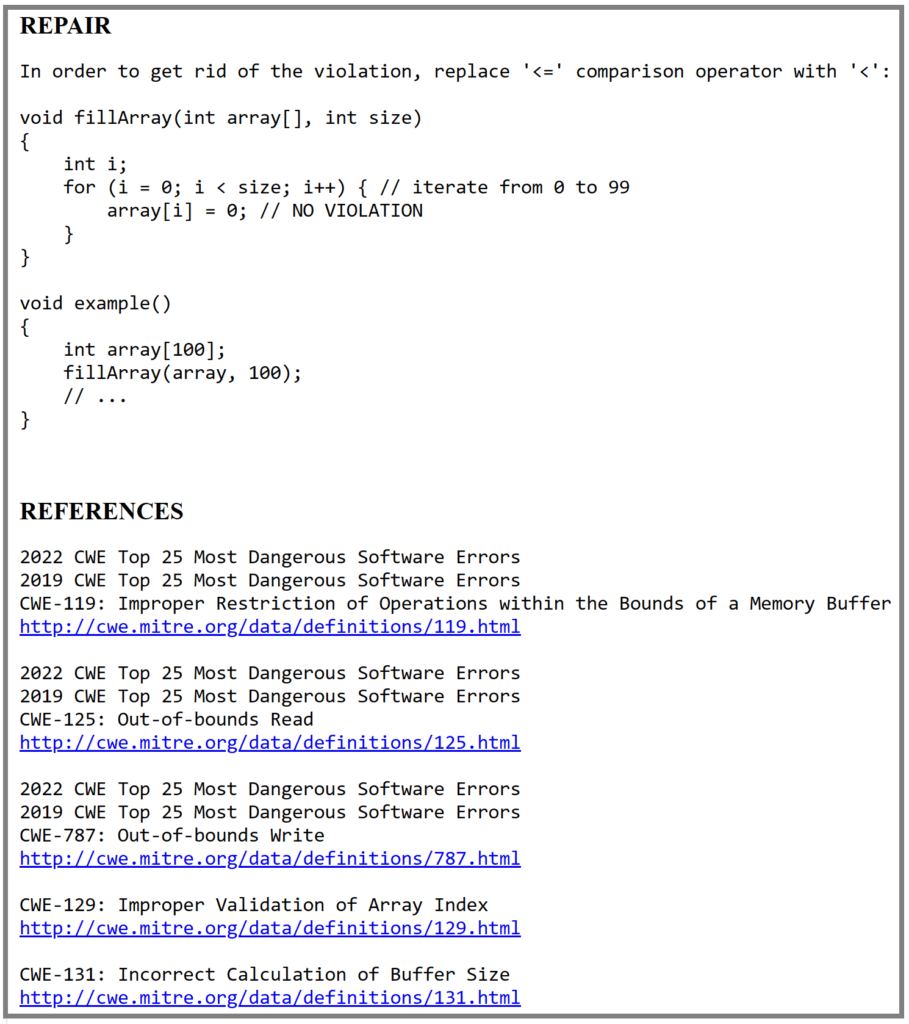
Accurate detection along with supporting information and remediation recommendations are critical for making static analysis and early detection of these vulnerabilities useful and immediately actionable for developers.
Preventing Buffer Overflows and Other Memory Management Errors
The ideal time and place to prevent buffer overflows is when developers are writing code in their IDE. Teams that are adopting secure coding standards such as SEI CERT C for C and C++ and OWASP Top 10 for Java and .NET or CWE Top 25, all have guidelines that warn about memory management errors.
For example, CERT C includes the following rules for memory management:

These rules include preventative coding techniques that avoid memory management errors in the first place. Each set of rules includes a risk assessment along with remediation costs, allowing software teams to prioritize the guidelines as follows:
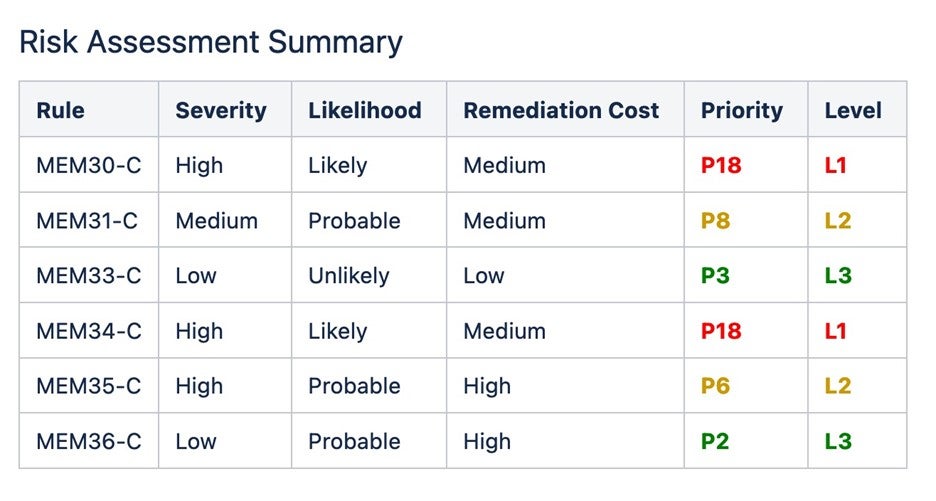
In the CERT C usage of the word, rule, violating a rule is most likely to cause a defect, and compliance should be done automatically or manually through inspection of the code. Rules are considered to be obligatory. Any exceptions made for rule violations must be documented.
On the other hand, a recommendation provides guidance that, when followed, should improve safety, reliability, and security. However, a violation of a recommendation does not necessarily indicate the presence of a defect in the code. Recommendations are not obligatory.
CERT C has the following recommendations for memory management:

The associated risk assessment is as follows for these recommendations:
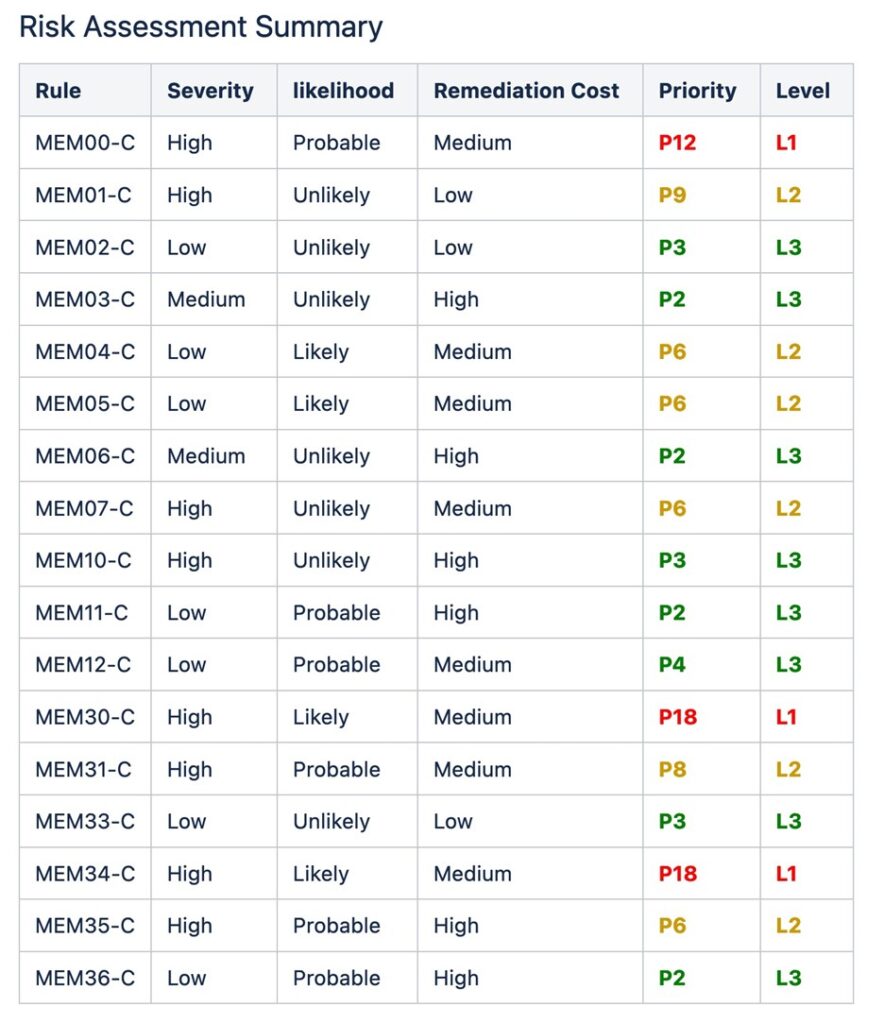
A key prevention strategy is to adopt a coding standard adapted from industry guidelines like SEI CERT and enforce it in future coding. Prevention of these vulnerabilities with better coding practices is cheaper, less risky, and has the highest return on investment.
Running static analysis of the newly created code is fast and simple. It’s easy for teams to integrate both on the desktop IDE and into the CI/CD process. To prevent this code from ever making it into the build, it’s good practice to investigate any security warnings and unsafe coding practices at this stage.
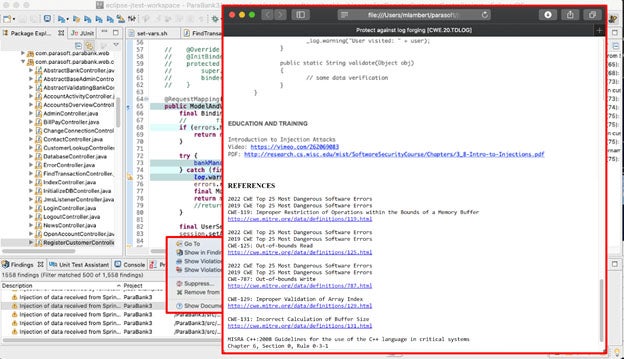
An equally important part of detecting poor coding practices is how useful the reports are. It’s important to understand the root cause of static analysis violations to fix them quickly and efficiently. This is where commercial tools such as Parasoft’s C/C++test, dotTEST, and Jtest shine.
Parasoft’s automated testing tools give full traces for warnings, illustrate these within the IDE, and collect build and other information on a continuous basis. This collected data alongside test results and metrics provides a comprehensive view of compliance with the team’s coding standard along with general quality and security status.
Developers can further filter findings based on other contextual information such as metadata on the project, the age of the code, and the developer or team responsible for the code. Tools like Parasoft with artificial intelligence (AI) and machine learning (ML) use this information to help further determine the most critical issues.
The dashboards and reports include the risk models that are part of the information provided by OWASP, CERT, and CWE. That way, developers better understand the impact of the potential vulnerabilities reported by the tool and which of these vulnerabilities to prioritize. All the data generated at the IDE level is correlated with downstream activities outlined above.
Conclusion: Safeguarding Your Code Against Buffer Overflows
The buffer overflows and other memory management errors continue to plague applications. They remain a leading cause of security vulnerabilities. Despite knowledge of how it works and is exploited, it remains prevalent. See the IoT Hall of Shame for recent examples.
We propose a prevent-and-detect approach to complement active security testing that prevents buffer overflows before they are written into the code as early as possible in the SDLC. Preventing such memory management errors at the IDE and detecting them in the CI/CD pipeline is key to routing them out of your software.
Smart software teams can minimize memory management errors. They can make an impact on quality and security with the right processes, tools, and automation in their existing workflows.
How to Select and Implement the Right Secure Coding Standard
Recommended Content

